Summary: A taxonomy is a backstage structure that complements the visible navigation. Taxonomies support consistent information retrieval by creating formal metadata rules.
What is a taxonomy and why does it matter for UX practitioners? In our UX Conference Information Architecture course, I often get asked what a taxonomy is, how to build one, and how it fits into the larger landscape of information-architecture (IA) work.
Taxonomies are what information-science professionals call controlled vocabularies — planned, prescriptive ways of adding descriptive metadata to content so that it can be retrieved effectively. The idea is that the taxonomy defines a limited set of terms for describing our content in the background; content creators must attach them to any new piece of content, with no ability to expand this vocabulary on an ad hoc basis.
Definition: A taxonomy is closed list of acceptable terms that are arranged hierarchically and are used to describe and classify content.
An example taxonomy: each piece of content on a website would be tagged with one or more of these terms to make it easy for the backend to direct the user to appropriate, related content.
Taxonomies are essentially controlled tag systems — while each piece of content will have a set of taxonomy terms attached to it, content creators cannot define their own terms. Each time we tag content using a taxonomy, we must follow some ground rules about which terms to use and how those terms relate to other terms.
It’s important to note that a taxonomy is different from the navigation structure that users interact with and from the underlying IA structure. More on this below.
4 Types of Organization Models in IA
Admittedly, information architecture can be a confusing discipline — there are many different types of abstract organization models that all seem quite similar but map out different things. The major four organization models are listed below:
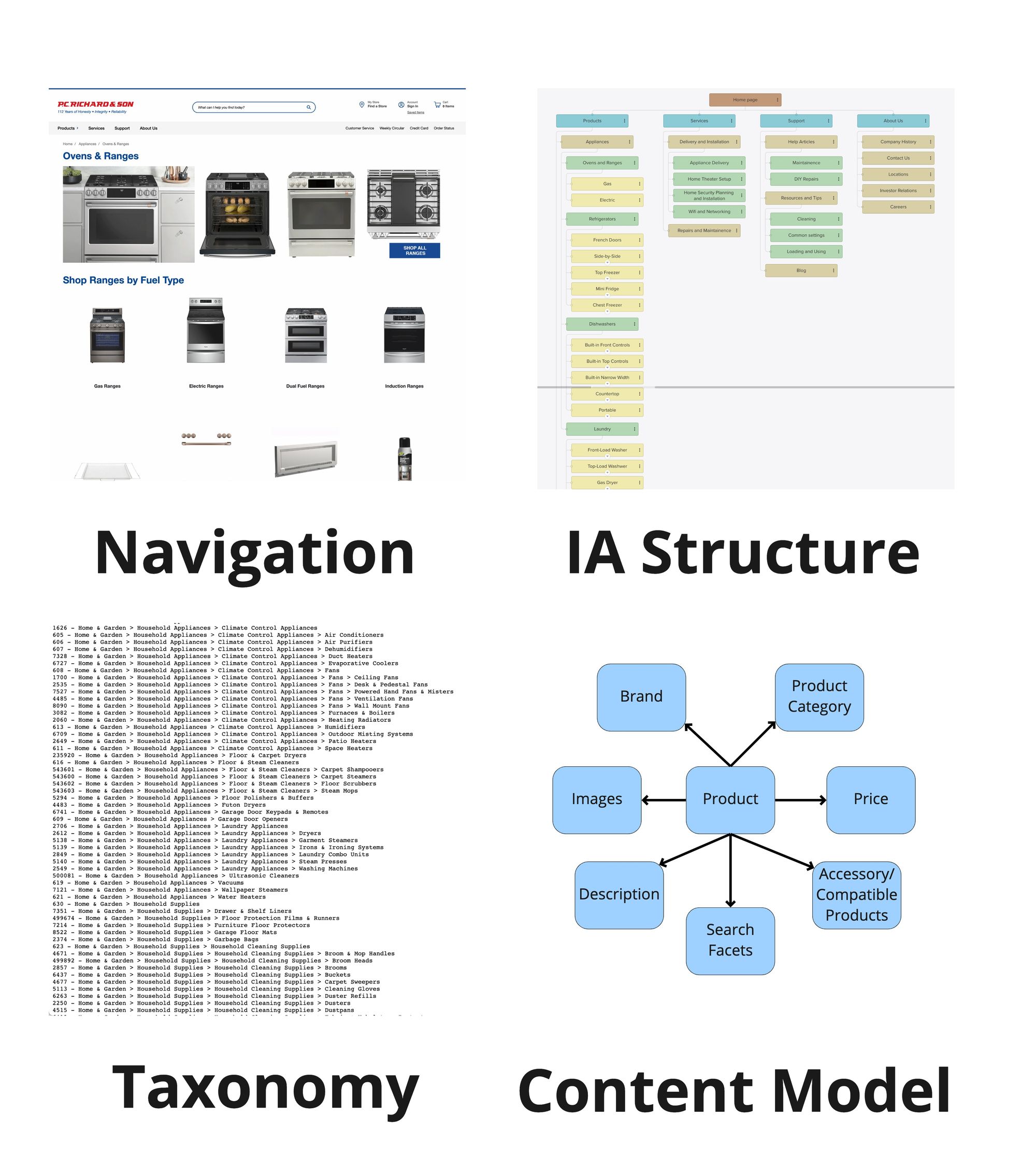
The 4 types of organization models in IA: The navigation is a user-visible partial view of the full underlying IA structure, which isn’t visible to users. The taxonomy is a separate hierarchical metadata structure that controls the specific terms (i.e., concepts) used to describe the content within the IA structure. A content model shows the relationships between different content types. (Taxonomy screenshot source)
- Navigation is a series of UI elements (menus, links, breadcrumbs, and accordions) that show the user which page or screen they are currently viewing and where they can go. In service- design lingo, navigation is frontstage (i.e., visible to users).
- IA structure (sometimes called a site map) is a map of all the key nodes of a site (e.g., pages or screens) and the relationships between them. The IA is part of the backstage — it isn’t directly shown to users, but it is used by the team to design the navigation or decide where a piece of content should go. The IA is usually similar to the navigation, but much more expanded — it is the full plan of all the content on the website, rather than the little slice a user can see at one time. Think of a huge office building — the signage and elevators form the navigation (but you can’t see the whole building all at once), whereas the architectural blueprint shows the full underlying building structure and is equivalent of the IA.
(Information architects and taxonomists frequently debate as to whether the IA tree structure constitutes a taxonomy – one could argue that this is a very loose form of taxonomy, but for our purpose we will differentiate this from a formal metadata taxonomy. The meta-classification irony is not lost on me!)
- Taxonomies (and other types of controlled vocabularies) are metadata we use to describe each bit of content (e.g. pages, text, data, products, help articles, files, etc.) and make connections to other content that’s similar.
Whereas the IA structure is a map of how our content is organized, a taxonomy is a map of concepts we use to describe our content and of how all those concepts relate to one another. A taxonomy is often very different than the IA structure or the navigation and is usually broader than and more technical than the two.
Because the taxonomy itself isn’t shown to users per se (though we may show some of the topics or tags to users as a form of navigation, search suggestions, or refinements), it’s a place where we can be fully immersed in very precise and logical classification work. We are typically concerned with logical precision in a taxonomy, whereas in the visible navigation structure we are concerned with grouping things in a way that adheres to users’ mental models.
- Content (or data) models are also part of the backstage, used to describe the different types of content, the information do they contain, how they are linked to other content types, what metadata applies to them, and so on.
For example, an NN/g Article has Author(s), which link to those author’s profile pages, Topics (that link to other content with that same topic, and if available, full topic-overview pages), and so on.
Why Create Taxonomies and Why Should UXers Be Involved?
Taxonomies aren’t created for the pure love of classifying things (though some UXers like myself absolutely love doing it). Taxonomies allow us to effectively retrieve all the content that is related to a specific concept. They are typically used in a few ways:
- Making connections between content. Related-content widgets often pull content that is within the same taxonomic category, even if it’s in a different navigation category.For example, on the NN/g site, the related articles that you can see below this article are pulled from our internal taxonomy of topics, which is much more granular and specific than the high-level topics that you might see listed on our site (e.g., this article belongs to the topic Information Architecture, but backstage we use the more the detailed classification Information Architecture>Metadata>Controlled Vocabularies>Taxonomy).
- Faceted navigation. Facets, which allow users to apply multiple filters simultaneously, are based on faceted taxonomies. Facets allow users to get extremely specific with their information needs without tediously browsing through a deep navigation tree.
The Library of Congress features search facets (along the left) for Topic, Part of/Collection, and Original Format, supporting very specific information needs without requiring users to dive deep into tedious hierarchies. This faceted navigation is enabled by a robust faceted taxonomy.
- Search suggestions and refinements. When users are typing in their search queries, the system can reference the taxonomy and pull results from related terms (that differ from what the user typed), It can also present categories to scope the user’s search.
The World Bank’s search suggestions for “europe pop…” reference the site’s taxonomy to list the preferred term: Population, total, European Union”, along with other specific categories related to population.
Other Types of Controlled Vocabularies: Thesauri and Ontologies
Another common area of confusion regards the difference between a taxonomy, a thesaurus, an Ontology, and a knowledge graph. They are all forms of metadata used for classification. They can all be represented as graphs in which the nodes are concepts and the edges are different kinds of relationships between these concepts.
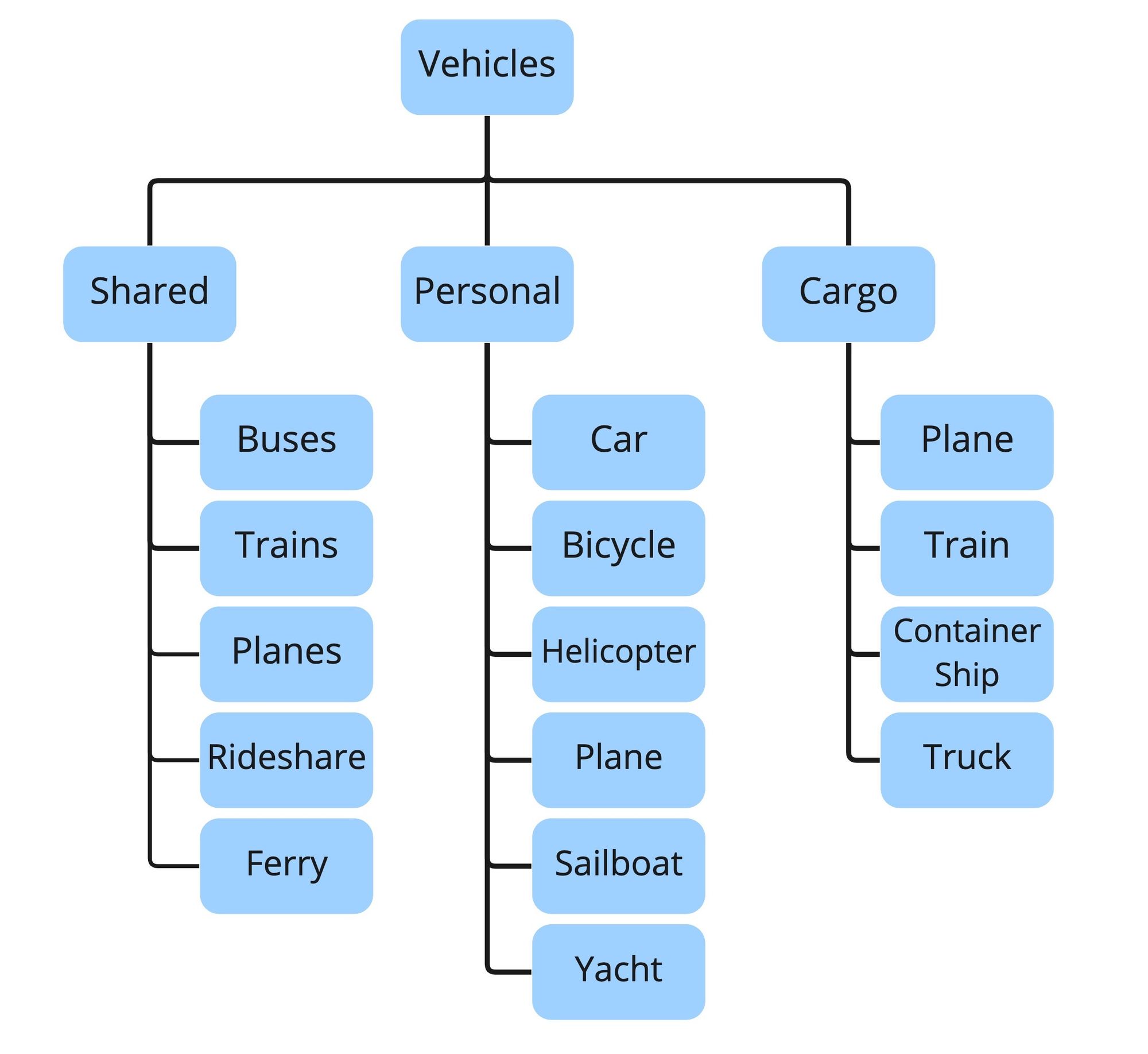
Taxonomies are the simplest of these structures. A taxonomy can be either hierarchical or faceted. A faceted taxonomy is made up of several hierarchical , distinct taxonomies that work together to describe different aspects of the same resource. Taxonomies revolve around parent-child relationships between concepts. As you go deeper into a taxonomy, the concepts become more specific (they can also be parts of a larger whole).
A hierarchical taxonomy of vehicle types (top) allows for only one “lens” or organizing principle (in this case, whether a vehicle is shared, personal, or cargo).A faceted taxonomy (bottom) has a separate small hierarchy for each facet or attribute. This type of taxonomy allows for combinations of characteristics that are very detailed.
A thesaurus (confusingly, not the dictionary type of thesaurus) is a data structure that includes not only parent–child relationships between concepts, but also associative relationships (“related term” that is not a synonym, but is conceptually related) and equivalence relationships (synonymous terms, with one being the official preferred term and the rest nonpreferred terms). A thesaurus allows for synonym control and consistency, which is incredibly important for complete information retrieval.
For example, if in your company’s intranet you have tags for RFP, Proposal, Statement of Work, and Pitch, but informally they’re all used interchangeably, then each one of these tags will only be associated with some of the relevant content, and, therefore, if you search for just one of the terms, you’ll get incomplete results. A thesaurus can link all those concepts together as either related or synonymous (with one chosen as the preferred term). So, in this case, we would probably have Proposal and Pitch be in an equivalence relationship, with Proposal being the preferred term. Both these concepts would be in an associative relationship to RFP and Statement of Work, because they are not exactly synonymous, but definitely conceptually related. (Note: Most “taxonomies” created for digital products are actually thesauri, since the software for managing taxonomies usually includes thesaurus features such as preferred terms and related terms.)
Ontologies are the most flexible and complex of these types of metadata structures and are often used for mapping out knowledge in complex technical fields. Ontologies support many different types of meaningful relationships (beyond parent–child, associative, and equivalence relationships) that connect concepts semantically.
For example, in the Linnean biology taxonomy that many of us had to learn in school, a polar bear (Ursus Maritimius) is a specific type of bear (Ursidae), which is a specific type of Carnivora (and so on). We are limited to only the one type of relationship — parent–child (or class-inclusion relationships). In an ontology, we can map out other types of conceptual connections: not only is a Polar Bear a type of Bear , but also its Habitat is Polar, its Conservation Status is Threatened, and so on. By building out these relationships of what we can formalize about a field of knowledge, we capture many other aspects into a formal structure that can then be used to build a database.
A biology taxonomy, zoomed into to show how polar bears are classified, is based on a single parent–child (or class –member) relationship.
Ontologies can go beyond parent–child relationships to capture other sorts of information relationships, such as the polar bear’s conservation status, its habitat, and potentially many other properties.
The flexibility of ontologies to represent many kinds of relationships among concepts allows for detailed multidimensional classification of information.
Ontologies are big, complex projects, typically used to describe a specific knowledge domain. These are not typically the type of project that a single UXer will take on by themselves, as they are often the work of a team of ontologists, taxonomists, software developers, and domain experts. It is, however, important to be aware of them, and how they relate to taxonomies. Especially if you work in scientific fields or on semantic-web projects, ontologies are something you are likely to encounter, so understanding what they are is helpful for a UX practitioner.
Building a Taxonomy
Building a taxonomy from scratch is a fairly involved process, and full details on how to do so are out of the scope of this article, but there are some common themes for how to proceed no matter the type of project. It is okay to start small and that a taxonomy need not be a multi-year project — simply having a small set of topics that you assign consistently to your content in the background is a fine start!
- Inventory and audit your content to start. You can’t organize something without knowing what you’ll be organizing.
- Look to see if there is a standard taxonomy for your industry or domain available first. If there is an existing taxonomy, then you can potentially get a big head start — you may need to modify it to suit your specific context, but it may save you a lot of work. Note that existing taxonomies vary in cost — some are free and open source, others are quite costly and require licensing. An excellent starting point is to review BARTOC.org to see what’s available.
- Identify the concepts that you will build your taxonomy around. These can be found in the content itself, any existing metadata (like keywords or topics in your content-management-system), discussions with subject-matter experts, and key internal business terms. The concepts should also be sourced from existing user data, such as that resulted from interviews, usability testing, and search logs to ensure that you don’t build out branches of the taxonomy that won’t benefit users.
- For each key concept that you identify, capture some information about other similar, related concepts or words and where the source of this concept was (such as the URL on a website).
- Evaluate your candidate terms. Look for relevance to user needs and avoid “singularities” — terms that aren’t related to anything else or terms for which you have only little coverage of the topic. Including concepts associated with only one piece of content is probably wasted effort.
- Decide on the preferred term and nonpreferred variants for each concept. Since the full taxonomy won’t be shown directly to users, you have a little more latitude here to use internal business jargon than you would in navigation, but it’s still advisable to choose preferred terms that have high information scent for users, as you may expose some of the terms in topics links or search suggestions. The best practice is to choose a user-friendly term as your preferred term and link internal business jargon or more technical language as nonpreferred synonyms.
- Build out the relationships between concepts. For a hierarchical taxonomy, this means defining the branches of your tree and deciding on the parent–child relationships between concepts. This is where the bulk of the work happens, as you need to decide on the granularity of each tier in the hierarchy. At this point, you will also identify related concepts that aren’t synonyms and connect those with related-term relationships (so, technically, you will also build your thesaurus).
- Review and revise your taxonomy with your stakeholders, internal subject-matter experts, and content strategists. This process is likely to involve iterative refinement, and it is up to the UXer to bring the user’s perspective into these conversations (especially around the choice of preferred terms).
- Apply the taxonomy to your content. Depending on the amount of content you are dealing with, this is going to be a significant effort and will require training the tagger on how to use the taxonomy (i.e., when to use one term as opposed to another). Of course, there are AI tools for automatic classification, but expect that they will make mistakes and that manual refinement and editing will be needed.
- Set up ongoing governance and maintenance. The long-term usefulness of the taxonomy depends on having regular reviews to add, rename, merge, or remove terms, and also to spot-check examples of how content has been tagged to ensure that the taxonomy is used properly.
Summary
Taxonomies are a powerful way to build content relationships in digital products and are the unseen, backstage organization systems that fill in the gaps that user-facing navigation systems may leave. When properly defined and maintained, a taxonomy can support better search suggestions and post-search refinements, faceted navigation, and automatic linking of related content.
Sources
Dean Allemang, James Hendler. 2011. Semantic Web for the Working Ontologist (2nd. Ed.). Morgan Kauffman, Waltham, MA.
Heather Hedden. 2016. The Accidental Taxonomist (2nd Ed.). Information Today, Medford, NJ.
International Organization for Standardization. (2011) Information and documentation — Thesauri and interoperability with other vocabularies — Part 1: Thesauri for information retrieval (ISO Standard No. 25964-1:2011) Retrieved from https://www.iso.org/standard/53657.html
Mary Whittaker and Kathryn Breininger. 2008. Taxonomy Development for Knowledge Management. In World Library and Information Congress: 74th Ifla General Conference and Council, 10-14 August 2008, Québec, Canada http://www.ifla.org/IV/ifla74/index.htm